Introduction
As cyber threats continue to evolve and become increasingly sophisticated, safeguarding your servers is more important than ever. One effective way to fortify your systems against unwarranted intrusion is by employing an intrusion prevention software tool like Fail2Ban.
Fail2Ban is an open-source software that protects your system against brute-force attacks. By scanning log files for any malicious activity, it identifies and bans IP addresses displaying suspicious behavior. It does this by dynamically altering the firewall rules to reject incoming connections from these addresses. This vital tool not only enhances your system’s security but also conserves resources that would otherwise be expended handling invalid requests.
In this comprehensive guide, we delve into the nuts and bolts of Fail2Ban – how to install it, configure it, and make it an effective component of your security strategy. Primarily, our focus will be on the installation and configuration of Fail2Ban on two popular Linux distributions – Ubuntu 20.04 and Red Hat Enterprise Linux (RHEL) 8.
Whether you’re a system administrator looking to enhance your server security or a tech enthusiast eager to broaden your knowledge about open-source security software, this guide is tailored to meet your needs. We’ll cover everything from basic installation procedures to advanced configurations, providing practical examples to illustrate each point clearly. Moreover, we’ll address common issues that might arise during the process and offer potential solutions.
Understanding Fail2Ban
To maximize the benefits Fail2Ban offers, we must first understand its workings, features, and components. This knowledge lays the foundation for proficiently installing and configuring this essential security tool.
Fail2Ban is a powerful open-source software that serves as an intrusion prevention system. It operates by continually monitoring your system’s log files for any signs of malicious activity such as repeated failed login attempts – often a telltale sign of a brute-force attack. When it detects such activity, Fail2Ban swings into action, blocking the offending IP address from making further connections.
At the heart of Fail2Ban’s operation are three main components: filters, actions, and jails.
Filters are a set of definitions or rules that Fail2Ban uses to parse the log files. These rules help Fail2Ban identify patterns of suspicious behavior.
Actions define what Fail2Ban should do once it identifies a potential threat. Typically, an action involves altering the firewall rules to block the offending IP address. However, actions can also include sending email notifications about the event.
The bridge between filters and actions is the jail. A jail in Fail2Ban binds a specific filter with an action. Essentially, a jail specifies that if certain suspicious activity is detected (as defined by the filter), a particular action should be taken.
Moreover, Fail2Ban is highly configurable, allowing you to define custom rules and actions that best suit your security needs. You can modify the ban duration, specify certain IP addresses to ignore, adjust the threshold for banning an IP, and much more.
Sure! Here’s the reformatted text with the command lines presented as code in the Gutenberg editor for WordPress:
Before we start, it’s important to remember that we will be making significant changes to the system. Ensure you have backed up any crucial data and proceed with caution.
1. Installing Fail2Ban on Ubuntu 20.04
Fail2Ban is available in the standard Ubuntu 20.04 repositories, which makes its installation straightforward. Here is a step-by-step guide on how to do it:
Step 1: Update your System
Before installing any new package, it’s always a good idea to update your system. Open a terminal and run the following command:
sudo apt update && sudo apt upgrade -yThis command will fetch the list of available updates and install them on your system.
Step 2: Install Fail2Ban
With your system updated, you can now install Fail2Ban using the following command:
sudo apt install fail2ban -yWait for the installation process to complete.
Step 3: Verify the Installation
Once the installation is complete, verify if Fail2Ban is installed correctly and running with this command:
sudo systemctl status fail2banYou should see a message indicating that Fail2Ban is active and running.
Step 4: Enable Fail2Ban to Start on Boot
To ensure that Fail2Ban starts automatically every time your system boots, use the following command:
sudo systemctl enable fail2banCongratulations! You have successfully installed Fail2Ban on your Ubuntu 20.04 system. In the following sections, we will discuss how to configure Fail2Ban and customize it to meet your specific needs. But before we proceed, let’s understand how to install Fail2Ban on a RHEL 8 system.
Certainly! Here’s the reformatted text with the headings and command lines presented as code in the Gutenberg editor for WordPress:
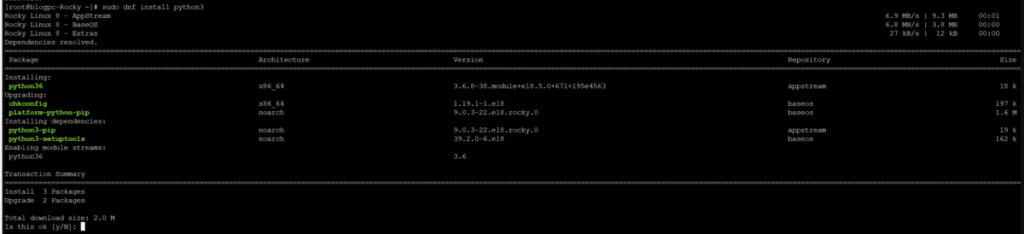
2. Installing Fail2Ban on RHEL 8
Just like in Ubuntu, Fail2Ban is readily available from the standard repositories in RHEL 8, simplifying the installation process. Let’s walk through this process step-by-step:
Step 1: Update Your System
Before installing new packages, it is recommended to update your system. Open your terminal and type:
sudo dnf update -yThis command will fetch the list of available updates and install them.
Step 2: Install the EPEL Repository
The Fail2Ban package is part of the Extra Packages for Enterprise Linux (EPEL) repository, which is not enabled by default. To install it, use the following command:
sudo dnf install epel-release -yStep 3: Install Fail2Ban
With the EPEL repository enabled, you can now install Fail2Ban. Type the following command in the terminal:
sudo dnf install fail2ban -yWait for the process to finish before moving to the next step.
Step 4: Check the Installation
Once the installation is complete, you can check if Fail2Ban is installed and running by using this command:
sudo systemctl status fail2banIf Fail2Ban is running successfully, you should see a message indicating that the service is active.
Step 5: Enable Fail2Ban to Start on Boot
Lastly, ensure Fail2Ban starts automatically at boot with the following command:
sudo systemctl enable fail2banAnd there you have it – Fail2Ban is now installed on your RHEL 8 system. In the upcoming sections, we’ll explore how to configure and customize Fail2Ban for optimal server security. Now that we have covered the installation process for both Ubuntu 20.04 and RHEL 8, we are ready to dive deeper into the world of Fail2Ban configurations.
Configuring Fail2ban
Understanding Fail2Ban Configuration Files
To effectively harness the power of Fail2Ban, it’s essential to understand its configuration files. The primary ones are jail.conf and jail.local, and they play a pivotal role in customizing Fail2Ban’s behavior to suit your unique needs.
1. The jail.conf File
The jail.conf file is the default configuration file that comes with the installation of Fail2Ban. It contains a series of “jails,” each of which associates a log file with one or more actions and filters. The jail.conf file contains numerous preset jails for various services like SSH, Apache, and more. Each jail specifies the rules that Fail2Ban follows when monitoring the log files for these services.
While you can directly modify jail.conf, it’s not recommended because this file may be overwritten when Fail2Ban is updated. Instead, it’s better to create and modify a jail.local file, as explained below.
2. The jail.local File
The jail.local file is where you should make your custom configuration changes. If this file is present, Fail2Ban will prioritize it over jail.conf. If it’s not present, you can create it by copying the jail.conf file. You can then modify this copy according to your needs. Any changes you make in jail.local will override the corresponding settings in jail.conf.
To create a jail.local file, use the following command:
sudo cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.localThen, open jail.local with a text editor of your choice (like nano or vim) and make your desired changes.
Creating and Modifying Filters
A filter in Fail2Ban defines the patterns to look for in a log file. Filters are stored in individual files within the /etc/fail2ban/filter.d/ directory. These files contain regular expressions (regex) that match patterns indicative of unauthorized or malicious activity.
Fail2Ban comes with many predefined filters, but you can also create your own. To do this, create a new file in the /etc/fail2ban/filter.d/ directory with a .conf extension, then add your regular expressions to this file.
For example, to create a new filter file called myfilter.conf, you would run:
sudo nano /etc/fail2ban/filter.d/myfilter.confThen, inside this file, you might add something like:
[Definition]
failregex = Failed login from <HOST>
ignoreregex =The failregex line defines the pattern that Fail2Ban will look for in the log files. <HOST> is a placeholder that matches any IP address.
Understanding how to work with these configuration files and filters is key to customizing Fail2Ban to suit your specific needs. In the next section, we will look at how to configure Fail2Ban on both Ubuntu 20.04 and RHEL 8, using the principles we’ve just discussed.
Customizing Fail2Ban Configurations for Ubuntu 20.04 and RHEL 8
Given the similarities between Ubuntu and RHEL regarding Fail2Ban configurations, the same steps can generally be applied to both. Let’s explore how to customize Fail2Ban to enhance the security of your server on both these platforms.
Step 1: Duplicating the jail.conf File
As a standard practice, refrain from modifying the original jail.conf file. Instead, create a duplicate named jail.local. Execute the command below to achieve this:
sudo cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.localStep 2: Accessing the jail.local File
Use a text editor to open and modify the jail.local file. We’ll use nano in this example:
sudo nano /etc/fail2ban/jail.localStep 3: Tailoring Fail2Ban Settings
Inside jail.local, there are two key areas to focus on: the [DEFAULT] section and the specific jail sections.
- Refining the [DEFAULT] Section
The [DEFAULT] segment contains settings applicable to all jails unless they are overridden in the individual jail sections. Significant parameters that you might want to customize include:
ignoreip: Specifies IP addresses that Fail2Ban will never ban. By default, it only includes 127.0.0.1 (localhost).bantime: Sets the ban duration (in seconds). The default is 600 seconds (10 minutes). If you desire to ban for an hour, for instance, set this to 3600.findtime: Determines the period (in seconds) within which Fail2Ban counts failed attempts. The default is also 600 seconds.maxretry: Specifies the number of failures (within thefindtime) that triggers a ban. The default is 5.- Adjusting Individual Jails
Post the [DEFAULT] section, you’ll find several individual jail sections for various services like [sshd], [apache], and more. Enable or disable these jails by setting enabled = true or enabled = false, respectively. Moreover, you can override any default settings within these jail sections.
Suppose you intend to activate the sshd jail and ban offending IPs for a day after three failed attempts within 15 minutes. In that case, you might modify the [sshd] section as follows:
[sshd]
enabled = true
bantime = 86400
findtime = 900
maxretry = 3Step 4: Saving and Exiting the File
Once you have made the desired changes, save and close the file. In nano, you can do this by pressing Ctrl+X, then Y, then Enter.
Step 5: Relaunching Fail2Ban
Apply your new configuration by restarting Fail2Ban with the following command:
sudo systemctl restart fail2banYou can now verify the status of Fail2Ban using sudo fail2ban-client status. The output should reflect the jails you’ve enabled.
Remember, this is just a primer to configuring Fail2Ban. The software is incredibly versatile, with a plethora of settings and options for you to fine-tune according to your security needs. For an in-depth understanding, consider exploring the official Fail2Ban documentation.
Implementing Advanced Fail2Ban Configurations
I. Banning Persistent Offenders
In the realm of server security, the persistent offenders – those that continuously attempt to breach your system – pose a significant threat. By exploiting different vulnerabilities or brute-forcing their way into the system, these relentless attackers can severely impact your server’s security and overall performance. Hence, it becomes crucial to have mechanisms in place to handle such persistent threats. One such mechanism involves leveraging Fail2Ban’s “recidive” jail. In this section, we will understand what “recidive” jail is and how to configure it to ban persistent offenders.
Understanding the ‘recidive’ Jail
Fail2Ban’s ‘recidive’ jail provides an extra layer of security to your server by handling repeat offenders who keep hitting the server even after being banned multiple times. The ‘recidive’ jail monitors Fail2Ban’s own log file and bans IPs that have been banned more than a certain number of times within a given period. These bans are usually much longer, helping to keep persistent attackers at bay.
Configuring the ‘recidive’ Jail
To configure the ‘recidive’ jail, open the jail.local file:
sudo nano /etc/fail2ban/jail.localFind the section labeled [recidive] and edit it as per your requirements. If it doesn’t exist, you can create one. Here is an example of a typical ‘recidive’ jail configuration:
[recidive]
enabled = true
filter = fail2ban
logpath = /var/log/fail2ban.log
banaction = iptables-allports
bantime = 86400 ; 1 day
findtime = 604800 ; 1 week
maxretry = 5In the above configuration:
filter = fail2bantells Fail2Ban to use the default Fail2Ban filter which matches lines in the log file indicating a ban.logpath = /var/log/fail2ban.logsets the log file to be monitored by this jail.banaction = iptables-allportssets the action to be taken when a ban occurs, which in this case is to ban the IP from all ports using iptables.bantime = 86400sets the ban duration to 1 day.findtime = 604800specifies that Fail2Ban should consider only the bans that have occurred within the last week.maxretry = 5means that an IP will be banned if it gets banned 5 times within one week.
Remember to replace the values as per your requirements.
Creating Custom Filters and Actions for Repeat Offenders
While the default ‘recidive’ jail configuration may be sufficient for many users, some may wish to create custom filters or actions for handling persistent offenders.
For example, suppose you wish to create a custom action that not only bans the IP but also sends an email alert whenever a persistent offender is banned. In that case, you can define a custom action file under the /etc/fail2ban/action.d/ directory, and then specify that action in your ‘recidive’ jail configuration.
Remember to always test your custom filters and actions to ensure that they work as expected before applying them to your live server.
Banning persistent offenders is an essential part of securing your server. By understanding how to configure the ‘recidive’ jail in Fail2Ban, you can effectively protect your server from repeated attacks.
II. Configuring Email Alerts
Alerts serve as critical components in any security system, promptly notifying administrators of any potential security issues. In the context of Fail2Ban, email alerts provide quick information about banned IPs and other security events, enabling administrators to take timely action. This section will detail the significance of email alerts and demonstrate how to configure email notifications in Fail2Ban.
The Importance of Email Alerts
Fast response to security incidents can mitigate potential damage and reduce the overall impact of an attack. Email alerts play a crucial role in this process by instantly informing system administrators about vital security events, such as an IP getting banned due to multiple failed login attempts. Furthermore, detailed email alerts can offer valuable insights into the nature of the attack, the offender’s IP, the service targeted, and the time of the event. All these details can contribute to a better understanding of the threat landscape and guide future security enhancements.
Email Notifications in Fail2Ban
Fail2Ban provides a built-in feature to send email notifications when an IP is banned. It uses the sendmail command by default to send emails. However, the exact mail command can be configured in the jail.local file. Besides the command, you can also specify the email address that should receive the alerts, the sender’s email address, and the format of the email.
Setting Up Email Alerts
Below are the step-by-step instructions on how to set up email alerts for banned IP addresses in Fail2Ban.
Step 1: Install Sendmail (if not already installed)
In Ubuntu 20.04 or RHEL 8, use the following command to install Sendmail:
sudo apt-get install sendmail # For Ubuntu
sudo dnf install sendmail # For RHELStep 2: Open the jail.local file
To configure email alerts, open the jail.local file in a text editor:
sudo nano /etc/fail2ban/jail.localStep 3: Configure the email settings
In the [DEFAULT] section of the jail.local file, set the following parameters:
destemail: The email address that should receive the alerts.sender: The sender’s email address (optional).mta: The mail transfer agent (default issendmail).action: The action to be taken when an IP is banned. To send an email alert, use theaction_mworaction_mwlaction. Theaction_mwaction sends an email with the whois report of the banned IP, while theaction_mwlaction sends an email with the whois report and relevant log lines.
Here is an example of how to configure these parameters:
[DEFAULT]
destemail = your-email@example.com
sender = fail2ban@example.com
mta = sendmail
action = %(action_mwl)sStep 4: Save and close the file
After making the changes, save and close the file. If you’re using nano, press Ctrl+X, then Y, then Enter.
Step 5: Restart Fail2Ban
Finally, restart Fail2Ban to apply the new settings:
sudo systemctl restart fail2banNow, whenever an IP gets banned, Fail2Ban will send an email alert to the specified email address.
In conclusion, setting up email alerts in Fail2Ban is a straightforward yet powerful way to enhance your server’s security. It ensures that you stay informed about critical security events and can take immediate action when needed.
III. Creating Custom Filters and Actions
Fail2Ban provides a powerful feature to create custom filters and actions. Custom filters allow you to define specific log patterns that Fail2Ban should consider as failed attempts, while custom actions define what Fail2Ban should do when it finds a match to these patterns. In this section, we will discuss the process of creating custom filters and actions, their use cases, and demonstrate how to set them up.
Understanding Custom Filters
A filter in Fail2Ban is a set of rules that define what log entries should be considered as failed attempts. Each filter is defined in a file located in the /etc/fail2ban/filter.d/ directory and uses regular expressions to match log entries.
Custom filters can be very useful in situations where the default filters don’t cover specific attack patterns. For instance, you might have services like FTP, SFTP, SMB, or SMTP running on your server, and you want Fail2Ban to ban IPs that make repeated failed login attempts to these services. In such cases, you can create custom filters to match the log entries generated by these services.
Creating Custom Filters
Here is an example of how you can create a custom filter for an FTP service:
- Create a new filter file: Open a new file in the
/etc/fail2ban/filter.d/directory, let’s name itcustom-ftp.conf:sudo nano /etc/fail2ban/filter.d/custom-ftp.conf - Define the filter rules: In the
custom-ftp.conffile, define the failregex that matches the failed login attempts in the FTP server’s log. For instance:[Definition] failregex = ^.*authentication failure;.* rhost=<HOST>$Replace thefailregexline with the actual log pattern of the failed login attempts. - Save and close the file: Press
Ctrl+X, thenY, thenEnterto save and close the file.
Defining Custom Actions
Custom actions in Fail2Ban define what should be done when a filter matches a log entry. For instance, you might want to run a specific script or command, send an email, or even sound an alarm when an IP gets banned. Custom actions can be defined in files located in the /etc/fail2ban/action.d/ directory.
Here is how you can create a custom action that sends an email with a custom message:
- Create a new action file: Open a new file in the
/etc/fail2ban/action.d/directory, let’s name itcustom-email.conf:sudo nano /etc/fail2ban/action.d/custom-email.conf - Define the action rules: In the
custom-email.conffile, define what should be done in theactionstart,actionstop,actioncheck,actionban, andactionunbansections. For instance, you can use themailcommand in theactionbansection to send an email when an IP is banned:[Definition] actionstart = actionstop = actioncheck = actionban = mail -s "Fail2Ban Alert: IP <ip> has been banned" your-email@example.com <<< "IP <ip> has been banned by Fail2Ban due to multiple failed login attempts to the FTP service." actionunban = - Save and close the file: Press
Ctrl+X, thenY, thenEnterto save and close the file.
Finally, don’t forget to restart Fail2Ban after creating or modifying filters and actions:
sudo systemctl restart fail2banBy understanding how to create custom filters and actions in Fail2Ban, you can enhance your server’s security and tailor it to your specific needs. Always ensure to test your custom filters and actions thoroughly to verify their functionality and impact on your server’s performance.
IV. Utilizing Fail2Ban APIs and External Scripts
The versatility of Fail2Ban extends beyond its in-built features. The software’s functionality can be further enhanced through the use of its APIs and the implementation of external scripts. These allow for a programmatic interaction with Fail2Ban, enabling you to create custom solutions tailored to your specific needs. In this section, we will explore how to leverage APIs and external scripts to extend the functionality of Fail2Ban and integrate it with other tools.
Interacting with Fail2Ban APIs
Fail2Ban, as of my knowledge cut-off in September 2021, doesn’t directly offer a REST API or similar interface for programmatic interaction. However, it does provide a Python-based API that allows you to interact with the Fail2Ban server programmatically.
By using this API, you can create, delete, and manage jails, fetch information about banned IPs, set the ban time, and perform many other actions. This can be particularly useful when you want to extend the functionality of Fail2Ban, or integrate it with other tools or systems.
Leveraging APIs for Extending Functionality
You can leverage Fail2Ban APIs to create custom solutions that extend its functionality. For example, you could write a Python script that automatically fetches the list of currently banned IPs and posts it to a Slack channel. Or you could create a web interface that displays real-time Fail2Ban statistics. The possibilities are virtually endless.
Implementing External Scripts for Custom Actions
Another way to enhance Fail2Ban’s functionality is by using external scripts. These scripts can be written in any language and can be triggered by Fail2Ban when certain events occur.
For instance, you might want to run a specific script when an IP gets banned or unbanned. You can do this by creating a custom action (as we discussed in the previous section) that calls your script.
Here is an example of a custom action that calls an external script:
- Create a new action file: Open a new file in the
/etc/fail2ban/action.d/directory, let’s name itcustom-script.conf:sudo nano /etc/fail2ban/action.d/custom-script.conf - Define the action rules: In the
custom-script.conffile, you can call your script in theactionbanoractionunbansections:[Definition] actionstart = actionstop = actioncheck = actionban = /path/to/your/script.sh <ip> actionunban = /path/to/your/other/script.sh <ip> - Save and close the file: Press
Ctrl+X, thenY, thenEnterto save and close the file.
V. Implementing Whitelists and Exemptions
While Fail2Ban is an essential tool for securing your server, there might be certain situations where you want to exempt specific IP addresses or services from being monitored by Fail2Ban. This is where the concept of whitelisting and exemptions comes into play. In this section, we’ll delve into the significance of implementing whitelists and exemptions, explain how to configure them in Fail2Ban, and present some common scenarios where they might be required.
The Importance of Whitelisting and Exemptions
In some circumstances, it might be necessary to whitelist certain trusted IP addresses, effectively excluding them from the scrutiny of Fail2Ban. This could be applicable, for instance, when you have specific IP addresses that need to continuously connect to your server, and you want to prevent them from being accidentally banned due to some unforeseen circumstances like a faulty login script.
Similarly, exemptions allow you to exclude certain services from Fail2Ban protection. For example, you might have an internal service that doesn’t require protection from Fail2Ban, and you want to avoid unnecessary load on your server by excluding this service from Fail2Ban’s monitoring.
Configuring Whitelists and Exemptions in Fail2Ban
To whitelist an IP address in Fail2Ban, you need to modify the ignoreip parameter in the jail.local file. Here’s how to do it:
- Open the jail.local file:
sudo nano /etc/fail2ban/jail.local - Add the IP address to the ignoreip parameter: In the
[DEFAULT]section of the file, add the IP address you want to whitelist to theignoreipparameter. You can specify multiple IP addresses separated by space:[DEFAULT] ignoreip = 127.0.0.1/8 ::1 192.168.0.100
To exempt a service from Fail2Ban, simply do not create a jail for that service in the jail.local file.
Scenarios for Whitelisting and Exemptions
Let’s consider some scenarios where you might want to implement whitelisting or exemptions.
- Trusted IP addresses: You might have certain IP addresses that belong to trusted users or administrators. These addresses can be whitelisted to prevent accidental bans.
- Fault-tolerant services: There might be some services in your server that have built-in security measures and don’t require additional protection from Fail2Ban. Such services can be exempted to reduce the load on the server.
- Internal services: Services that are only accessible internally and are not exposed to the internet can be exempted from Fail2Ban protection, as they pose a low risk of being attacked.
VI. Log Analysis and Visualization
Monitoring the behavior of your server is a critical aspect of maintaining its security. Fail2Ban logs provide valuable insights into security events and can help identify attack patterns and potential vulnerabilities. This section will discuss the importance of analyzing Fail2Ban logs, introduce tools and techniques for this purpose, and explain how to visualize Fail2Ban data for better understanding and interpretation.
The Importance of Log Analysis
Fail2Ban logs contain detailed information about its operations, including which IP addresses were banned, when they were banned, and which service triggered the ban. By analyzing these logs, you can identify patterns and trends, such as repeated attacks from the same IP address or a sudden surge in failed login attempts, indicating a possible brute-force attack.
Additionally, log analysis can also aid in troubleshooting and fine-tuning Fail2Ban’s configuration. For example, if a trusted IP address is being banned repeatedly, it may indicate that you need to adjust the fail2ban sensitivity or whitelist that IP.
Tools and Techniques for Log Analysis
There are several tools available for analyzing Fail2Ban logs. fail2ban-client, the command-line interface provided with Fail2Ban, offers several commands for viewing the current status of Fail2Ban, such as fail2ban-client status, which shows the status of all active jails.
For more advanced log analysis, you can use log management tools such as Logwatch, Logcheck, or GoAccess. These tools can parse the logs, identify important events, and provide reports.
You can also write custom scripts to analyze the logs. For instance, a simple Bash or Python script can parse the Fail2Ban log file and identify the most frequently banned IP addresses.
Visualizing Fail2Ban Data
Visual representation of data is a powerful way to understand complex patterns and trends. Tools such as Grafana or Kibana allow you to create dashboards for visualizing Fail2Ban logs. These dashboards can include graphs, charts, and tables that show the number of banned IPs over time, the most targeted services, the most frequently banned IPs, and more.
To visualize Fail2Ban data, you need to export the logs to a format that your visualization tool can understand. This can be done using a log shipper like Filebeat or Fluentd.
VII. Testing and Monitoring
Implementing advanced configurations in Fail2Ban, such as custom filters and actions, can significantly enhance your server’s security. However, it’s equally important to thoroughly test and monitor these configurations to ensure they’re working as expected and aren’t causing any unintended side effects. This section discusses the significance of testing and monitoring in Fail2Ban and provides guidelines on how to effectively test your custom configurations.
The Importance of Testing and Monitoring
While creating custom configurations in Fail2Ban provides a level of flexibility, it also brings in complexity. Even a minor mistake in a filter or action can lead to serious issues such as banning legitimate users or failing to ban malicious users. Hence, it’s crucial to thoroughly test your configurations to make sure they work correctly.
Furthermore, monitoring the performance and effectiveness of your Fail2Ban configurations can help you fine-tune them and adapt to changing circumstances. For example, if a particular filter is banning too many IP addresses, you might need to adjust its sensitivity. Similarly, if an action is not working as expected, monitoring can help you identify and fix the problem.
Testing Custom Filters, Actions, and Configurations
Fail2Ban provides a utility called fail2ban-regex that allows you to test your custom filters against your log files. This utility is a powerful tool to validate your filters before deploying them in a live environment. Here’s how to use it:
fail2ban-regex /path/to/your/logfile.log /etc/fail2ban/filter.d/your-filter.confThis command will test the filter defined in your-filter.conf against the log file logfile.log and show you the matched lines. This way, you can verify that your filter is catching the right log entries and adjust it if necessary.
For testing actions, unfortunately, there’s no built-in tool in Fail2Ban. The best way to test an action is to apply it to a temporary jail and trigger it manually. You can do this by setting the maxretry and findtime parameters to low values, which will cause the action to trigger quickly.
In conclusion, effective testing and monitoring are key to maintaining a secure and efficient Fail2Ban setup. They enable you to validate your custom configurations, detect issues early, and ensure your server remains secure against potential threats.
Troubleshooting Common Fail2Ban Issues
Like any robust software, encountering issues while installing or configuring Fail2Ban is not uncommon. These issues can vary, ranging from installation hurdles to difficulties during the configuration of filters or actions. This section aims to address some frequently occurring Fail2Ban challenges, providing pragmatic solutions and tips to troubleshoot these obstacles.
Installation Problems
A fairly common issue users may encounter relates to difficulties arising during the installation process. If you find yourself struggling to install Fail2Ban, it could be due to several factors:
Ensuring System Updates
First and foremost, make sure your system is up-to-date. You can accomplish this by running sudo apt update && sudo apt upgrade on Ubuntu or sudo yum update on RHEL.
Checking Repositories
If the package manager can’t find the Fail2Ban package, it may indicate that the required repositories aren’t enabled or your package list isn’t up-to-date.
Verifying Dependencies
When installing from source and encountering issues, ensure all the necessary dependencies are installed.
Filters Not Catching Log Entries
If your filters aren’t catching the log entries they should, several potential issues can be checked:
Log Path Mismatch
Ensure the log path in your jail configuration aligns with the actual location of your log files.
Using fail2ban-regex
The fail2ban-regex tool is quite handy for testing your filters against your log files. This tool can help pinpoint any mismatches or issues with your filter patterns.
Checking failregex
Make sure the failregex in your filter configuration is correctly formatted and captures the log entries you intend to ban.
Actions Failing to Trigger
If actions are not being triggered when they should be, consider the following troubleshooting steps:
Checking Jail Configuration
Make sure the action is correctly defined in your jail configuration.
Verifying Parameters
Check that the maxretry and bantime parameters are set appropriately.
Consulting Fail2Ban Logs
Consult your Fail2Ban logs (/var/log/fail2ban.log) for any error messages or warnings related to your actions.
Difficulties with Whitelisting
If whitelisting IP addresses presents a challenge:
Adding IPs Correctly
Ensure the IP addresses are correctly added to the ignoreip parameter in the jail.local file.
Restarting Fail2Ban Service
Remember to restart the Fail2Ban service after making changes to the configuration files.
In conclusion, by identifying and troubleshooting these common issues, you can ensure that your Fail2Ban installation functions as effectively as possible. Always double-check your configurations, and rigorously test your filters and actions before applying them to a live environment.
Conclusion
Securing your server environment is a crucial responsibility, and as we have seen throughout this blog post, Fail2Ban offers a powerful and flexible tool to help you do just that. From the basic installation process on different operating systems, to understanding and customizing its core configuration files, we’ve covered a wide range of topics that equip you with the knowledge to optimize Fail2Ban to your needs.
Initially, we delved into the basic installation steps on both Ubuntu 20.04 and RHEL 8, demonstrating that the process is quite straightforward, thanks to the package managers of these systems. Building upon that, we explored the intricate details of Fail2Ban’s configuration files – the jail.conf and jail.local files. We learned how to create and modify filters to match specific log entries, a critical aspect of tailoring Fail2Ban’s behavior.
In addition, we examined the process of configuring Fail2Ban to handle persistent offenders and discussed the importance of creating custom filters and actions. These steps allow you to refine Fail2Ban’s response to repeated threats and tailor its actions to match the unique security requirements of your server environment.
We also delved into the versatility of Fail2Ban’s APIs and how external scripts can further extend its capabilities. Furthermore, we discussed the need for whitelists and exemptions, understanding how to effectively implement them.
In summary, while Fail2Ban is a powerful tool, its effectiveness lies in proper configuration, regular monitoring, and adaptive management. As we’ve seen, the software offers numerous customization options that allow you to tailor its operations to your server’s unique needs. With careful implementation and monitoring, Fail2Ban can be an essential asset in your security toolkit.